

|
林之秋 投稿 量子位 | 公众号 QbitAI 视觉话语模子(如 GPT-4o、DALL-E 3)频繁领罕有十亿参数,且模子权重不公开,使得传统的白盒优化顺次(如反向传播)难以实验。 那么,有莫得更松驰的优化顺次呢? 就在最近,卡内基梅隆大学(CMU)的斟酌团队关于这个问题提议了一种立异的“黑盒优化”战略—— 通过谎话语模子自动调理应然话语领导词,使视觉话语模子在文生图、视觉识别等多个卑鄙任务中取得更好的发挥。 这一顺次不仅无需涉及模子里面参数,还大幅普及了优化的机动性与速率,让用户即使莫得本领布景也能松驰普及模子性能。 该斟酌已被 CVPR 2024 继承。  怎样作念到的? 大多数视觉话语模子(如 DALL-E 3、GPT-4o 等)并未公开模子权重或特征镶嵌,导致传统依赖反向传播的优化模样不再适用。 不外,这些模子频繁向用户盛开了当然话语接口,使得通过优化领导词来普及模子发挥成为可能。 但是,传统的领导词工程严重依赖工程师的教授和先验常识。 举例,为普及 CLIP 模子的视觉识别效果,OpenAI 破耗了一年时间网络了几十种有用的领导词模板(如 “A good photo of a [class]”)。 雷同,在使用DALL-E 3和Stable Diffusion等文生图模子时,用户经常也需掌抓浩荡领导词技能武艺生成安逸的末端。 那么,有莫得替代东谈主类领导词工程师的顺次? 有的 CMU 团队提议了一种新战略:用 ChatGPT 等谎话语模子自动优化领导词。 像领导词工程师诈欺响应矫正领导词一样,CMU 的顺次将正负响应交给 ChatGPT,以更高效地调理领导词,具体经过如图所示: 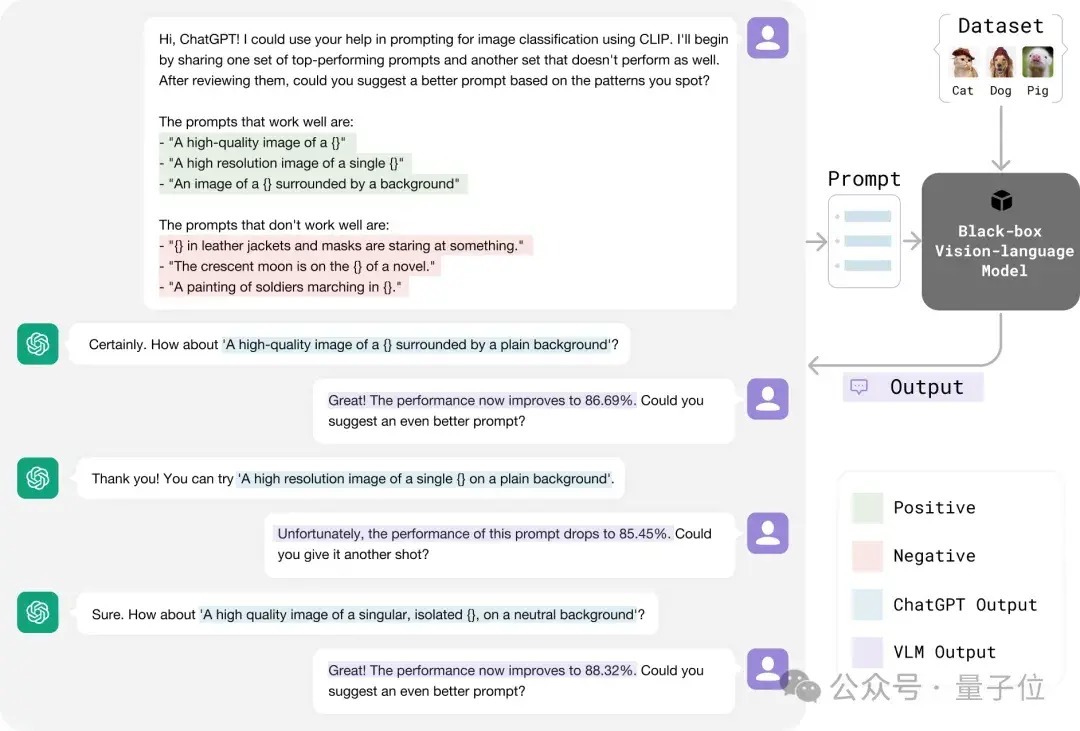 这种优化经过访佛于机器学习中的“爬山法”(hill-climbing)战略,不同之处在于谎话语模子不错自动分析领导词发挥,从正负响应中找到最优矫正目的。 斟酌团队诈欺这一特色来更高效地优化领导词。这个经过不错用以下门径抽象:  领导词运行化:网络一批未经优化的运行领导词。领导词排序:对刻下领导词进行发挥评分,保留高分领导词,替换低分领导词。生成新领导词:通过谎话语模子,确认领导词的发挥生成新的候选领导词。 经过多轮迭代,最终复返得分最高的领导词行为优化末端。 实验末端通过这一顺次,CMU 团队在无需东谈主类领导工程师参与的情况下,在多个小样本视觉识别数据集上取得了最好准确性,以至超过了传统的白盒领导词优化顺次(如 CoOp)。 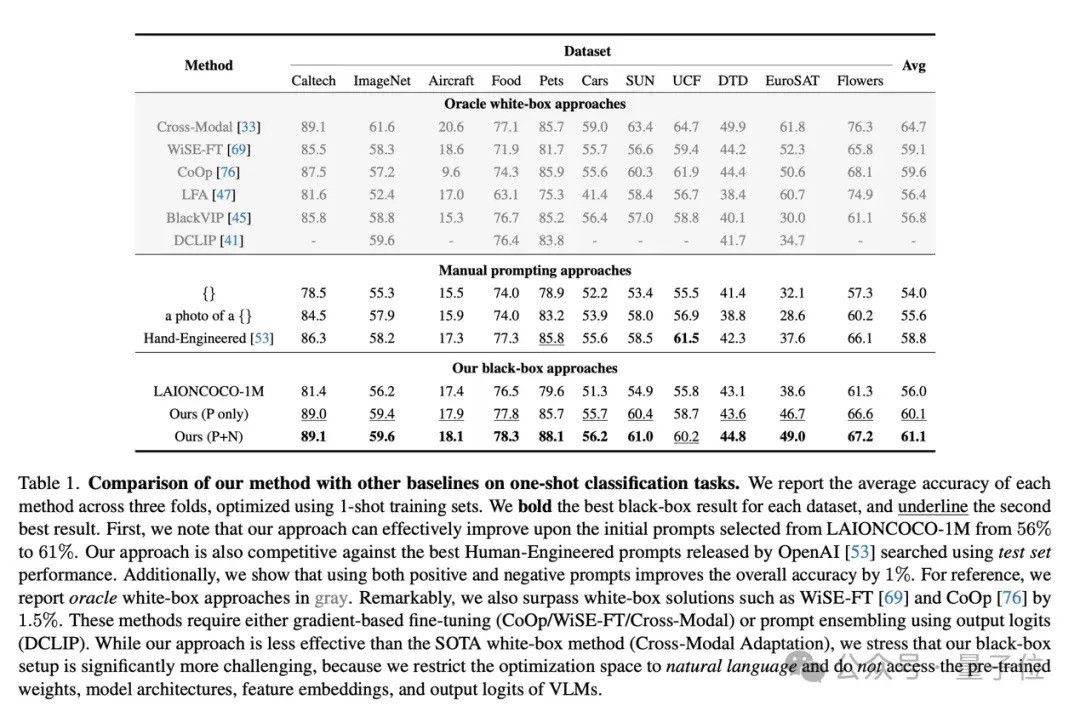 此外,该顺次在无需了解数据集实质的前提下,自动捕捉到了卑鄙任务的视觉特色并将其融入领导词中,取得了更好的效果。 举例,在食品识别任务中,ChatGPT 自动将领导词调理为识别“万般化的好意思食和原料”,从而普及了模子的发挥。  斟酌团队还证明了,通过 ChatGPT 黑盒优化得到的领导词不仅适用于单一模子架构,还能在不同模子架构(如 ResNet 和 ViT)之间泛化,况且在多种模子上发挥优于白盒优化得到的领导词。 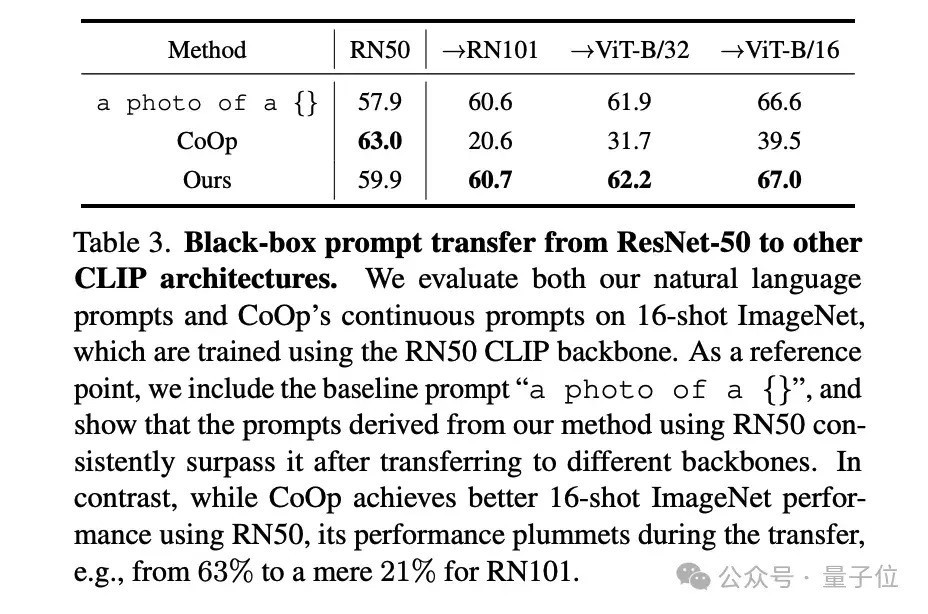 这一系列实考据明,谎话语模子大要从领导词的性能响应中索求出隐含的“梯度”目的,从而结束无需反向传播的模子优化。 在文生图任务中的应用CMU 团队进一步探索了该顺次在生成任务中的应用后劲。 在文本到图像生成(T2I)任务中,ChatGPT 大要自动优化领导词,从而生成更相宜用户需求的高质料图像。 举例,关于输入神情“一个动物预防着一个东谈主”,系统不错通过渐渐优化领导词来普及生成图像的准确性。 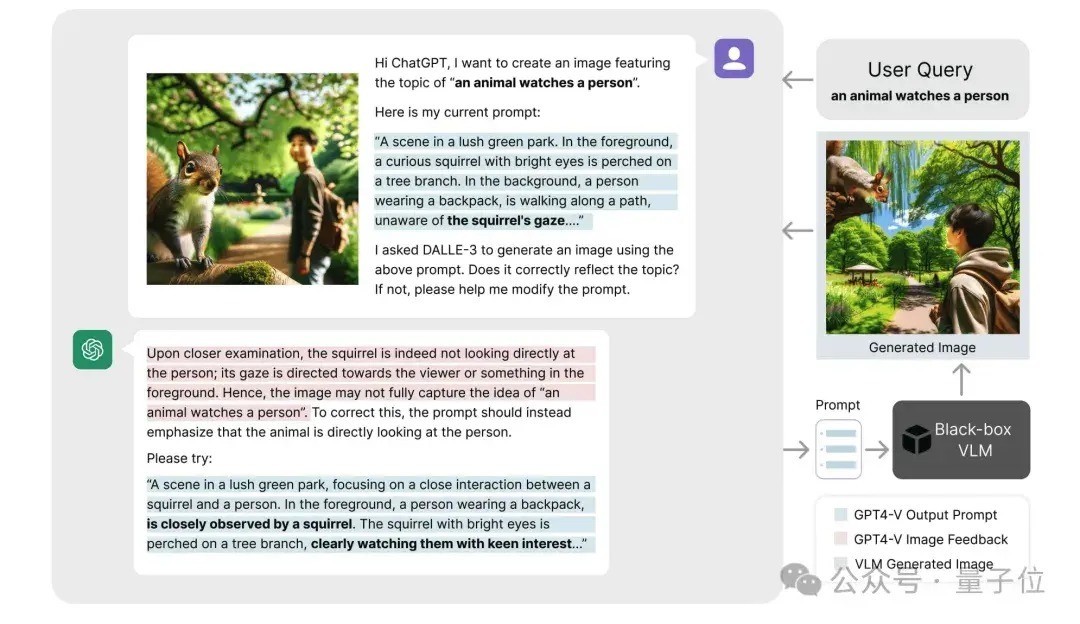 此外,这一顺次还适用于领导反演(Prompt Inversion)。 领导反演是一种确认现存图像反推生成模子输入领导词的本领,轻便来说,即是通过图像生成大要再现其特征的文本神情(领导词)。  斟酌团队在复杂的文本到图像任务上进行了测试,末端标明这一顺次仅需三轮领导词优化,就能显赫提高用户的安逸度。  此外,斟酌团队还指出,领导反演不错匡助用户快速定制特定的图像效果,举例“让这只狗酿成赠给姿势”或“让布景酿成夜景”,从而生成相宜特定需求的图像。  CMU 团队暗示,提议的黑盒优化范式打破了传统模子调优的放置,不仅在图像分类和生成任务中发挥出色,还展示了普通的应用后劲。 这一顺次无需拜访模子权重,仅通过“文本梯度”结束精确优化,具备巨大的推广性。 异日,黑盒优化有望应用于及时监控、自动驾驶、智能医疗等复杂动态场景,为多模态模子的调优带来愈加机动高效的处理决策。 团队先容团队的一作刘士弘(Shihong Liu)是卡内基梅隆大学的斟酌生毕业生,曾任机器东谈主斟酌所斟酌员。 当今在 北好意思Amazon 使命,安祥大型漫步式系统的盘算和谎话语模子驱动的 AI Agent 的建造。  △刘士弘(Shihong Liu) 团队的共磨灭作林之秋(Zhiqiu Lin)是卡内基梅隆大学的博士斟酌生,专注于视觉-话语大模子的自动评估与优化。 Zhiqiu Lin在CVPR、NeurIPS、ICML、ECCV等顶级会议上发表了十数篇论文,并曾荣获最好论文提名和最好短论文奖等。  △林之秋(Zhiqiu Lin) Deva Ramanan素养是盘算机视觉边界的外洋著名学者,现任卡内基梅隆大学素养。  △Deva Ramanan素养 他的斟酌涵盖盘算机视觉、机器学习和东谈主工智能边界,曾取得多项顶级学术荣誉,包括2009年的David Marr奖、2010年的PASCAL VOC毕生设置奖、2012年的IEEE PAMI后生斟酌员奖、2012年《巨匠科学》评比的“十位凸起科学家”之一、2013年好意思国国度科学院Kavli Fellow、2018年和2024年的Longuet-Higgins奖,以及因其代表性使命(如COCO数据集)取得的Koenderink奖。 此外,他的论文在CVPR、ECCV和ICCV上屡次取得最好论文提名及荣誉奖。他的斟酌着力对视觉识别、自动驾驶、和东谈主机交互等应用产生了长远影响,是该边界极具影响力的科学家之一。 CVPR’24论文贯穿: https://arxiv.org/abs/2309.05950论文代码: https://github.com/shihongl1998/LLM-as-a-blackbox-optimizer方式网站: https://llm-can-optimize-vlm.github.io— 完 — 量子位 QbitAI · 头条号签约 祥和咱们,第一时间获知前沿科技动态 |
